Projected Revenue Estimation from Crowdsourced Information on Statistical Errors

By Sam Savage (bio in sidebar) and Shayne Kavanagh (bio)
It is difficult for municipal financial officers to accurately estimate their tax revenues, especially during uncertain times such as the recession of 2008 to 2010 and the current COVID-19 pandemic. Customarily forecasts are based on a single number, with no indication of its chances of being met.
We are helping some CFOs of municipalities estimate the chances of meeting projections and are eager to help others as well. Read on to see how you can apply this approach within your own organization.
The goal of nonprofit ProbabilityManagement.org is to deliver statistical measures of uncertainties to non-experts as actionable data, much as power stations deliver energy to consumers as electricity. We have come to call this process chancification, because for the first time, it provides organizations with a standard approach for illuminating the chances of achieving their goals. In the example below, ProbabilityManagement.org teamed up with the Government Finance Officers Association (GFOA), a professional organization of over 21,000 financial managers, to bring chancification to municipal budgeting.
The ABCs of Chancification
The steps of Chancification are:
A. Assess the situation
B. Bound the uncertainty
C. Correlate the variables
D. Deliver stochastic libraries
E. Employ the results to improve decision making.
A: Assess the Situation
In 2015, GFOA did a study of the accuracy of tax revenue projections from around 30 municipalities. This resulted in a database containing forecast vs. actual revenues, crowdsourced across multiple tax categories, cities, and time periods.
B: Bound the Uncertainties
The data provided estimates of the bounds on the uncertainties in forecast accuracy. We quantified these with SPT Metalog distributions.

C: Correlate Variables
We used R to correlate the errors between tax categories.

D: Deliver Stochastic Libraries
We created libraries of forecast errors for two economic time periods, one good and one during the recession.

E: Employ Results
We created an Excel dashboard, linked to the library, that lets the user choose tax revenue types from a menu, specify the forecast for each, and then estimate the chances of achieving each tranche of a prioritized budget.
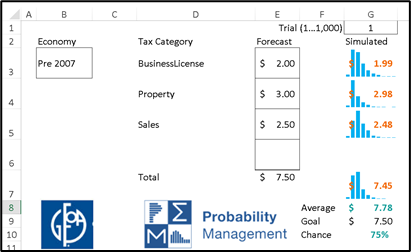
Thus, was born
Projected Revenue Estimation from Crowdsourced Information on Statistical Errors
or the PRECISE Uncertainty Project. It is indeed precise in the sense that the uncertainties are represented as auditable data; stochastic information packets (SIPs) that obey both the laws of arithmetic and the laws of probability.
Reference class forecasting, developed by Daniel Kahneman, Nobel Laureate in Economcs, is a method of predicting future outcomes based on similar experiences in the past. The PRECISE Uncertainty Project takes this approach further by creating reference class objects: individual interrelated forecasting errors of each revenue types, which may be combined using conventional arithmetic to predict the accuracy of the entire budget.
Last fall, we presented an early version of this work at Risk Awareness Week, a conference organized by Alex Sidorenko, Chief Risk Officer at EuroChem. In fact, it was Alex, a veritable impresario of risk, who first characterized this approach as “crowdsourced.”
We are now seeking volunteers to both experiment with this system and provide more historical accuracy data to expand the study. To learn more about how your organization can start down this path:
Attend our PRECISE Uncertainty webinar
Visit PreciseUncertainty.org
For full videos of all five probability management presentations at Risk Awareness Week, visit our Presentations page.
© Copyright 2021 Sam Savage and Shayne Kavanagh